
We like to share our thoughts and work so we can give back to the community a very small part of what we take from it every day.
On that spirit we decided to share a little bit on a project we’ve been working with a client on for some time now. The idea is to show some parts of what we’ve built for this client, the how, the why and the journey to get there. We hope this will inspire others to the the same and share their work so we can also learn from it.
Although we did get approval from our client to write about our story together we will not reveal it’s identity because we want to keep some level of discretion.
Some context first
This client is an established local company with international presence, several released products (both hardware devices and software) and a noticeable footprint on it’s target market. We started working with them on improving their infrastructure for the new phase of their company and some very exiting new products they will be releasing soon.
When they approached us they were looking to build a platform that could grant them some key features:
- A good developer experience
- Fast prototyping
- Reliability
- Elasticity
- Scaling potential
Our client was already looking into containerizing their environments and so Kubernetes was a obvious option for their type of workload.
After we got to know them and talked about what they envisioned for the future we decided Kubernetes was a a good approach and started to get our hands dirty.
Ground work
We started by getting the team together and exploring some base concepts for Docker and Kubernetes so all the team would feel as comfortable as possible with this change going forward. This was actually a requirement from our client which just goes to show how thoughtful their plan was right from the beginning.
We did a boot camp with the team, going through some key Docker concepts and exercises before taking a look at Kubernetes and how this would help them going into the future.
After everyone was comfortable with these new technologies and how we would apply them we started to work on the actual infrastructure side of the project.
To run Kubernetes workloads you need a Kubernetes cluster so that is exactly what we did – we created a Kubernetes cluster. For this first phase we did not use the usual cloud provider managed cluster. We created our own cluster running in our client’s infrastructure.
To build this cluster we used a project called Kubespray. It is a great help in setting up a Kubernetes clusters. It covers a wide spectrum of use cases: you can dive deep into each config or just go with the defaults and it will work very well out of the box.
Our requirements for this phase were quite simple and straight forward – A Kubernetes cluster with horizontal pod auto scaling.
After this was done we had something like this:
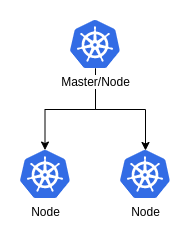
A couple of choices we took along the way:
- We have only one master – Not ideal but sufficient for this use case
- Our master is also a worker node – The cluster is not that big and the extra scheduling space is useful
We have a cluster, so the job must be done, right? Not really. There is no point in having a k8s cluster if you are not using it so: how are clients reaching it? 🤔
Because we don’t want to have one node get all the traffic and then potentially split it via the internal overlay network we need to have a way to split the traffic among the nodes. Enter HAProxy (you can learn a little bit more about HAProxy in our post about it – here).
We decided on HAProxy to be our point of entry due to it’s amazing feature set and incredible performance. We have also setup HAProxy such that it handles SSL termination for the environment, giving us a centralized location where to easily manage certificates.
We are not a company who likes to do things by hand over and over again so all of this is automated and managed by an Ansible playbook. This granted us the ability to rebuild our environment in a very short amount of time and in a consistent fashion. We know it because we did it already a couple of times.
We ended up with something like this:
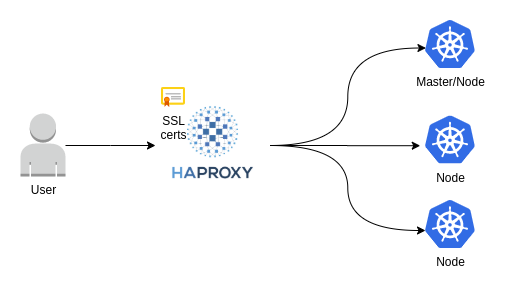
To really get all the juice out of Kubernetes we took it to another level and decided to gather all the environments on the same cluster. This allowed our client to get an impressive speed from idea to test to production while keeping the runtime environment consistent across stages. We’ve leveraged Kubernetes namespaces to keep each environment contained and it is working very well.
Extra quests
After we had most of the ground work completed we started to think about how to tackle some other problems that were in need of improvement.
CI/CD
Our client was already using a tool by Microsoft called Azure DevOps. As we were forced to change the CI and CD part to bring it to new environment we were tasked with helping them bring their CI/CD infrastructure along.
For this, we created a new Ansible playbook to configure CI/CD agents for our client with a simple command. We were able to streamline the whole process and so, provisioning new agents is as simple as running a command.
Logs and Metrics
From the beginning of this new approach we knew we needed to do something about logging and metrics. We want to keep our logs and metrics after our pods are long gone (look here if you want to know more of our thoughts on monitoring) and we want to be able to alert on some metrics when they go out of regular parameters.
Our client was on board when we proposed ELK stack as way to tackle this need. Again, we opted to use another Ansible playbook to manage our ELK server deployment and we got into a state like this:
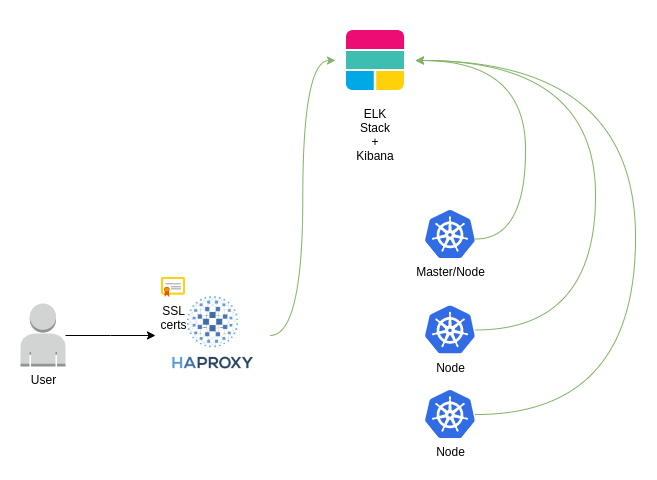
This sets up our client with the ability to track, not only, the HTTP request that comes into HAProxy but also each and every log produced by their services divided by environment, service, pod, node and much more. One other cool feature our client gained is to know where the external traffic is coming from just by looking at a map!
This isn’t the end of our work this client, we keep cooperating and trying to achieve better and greater things as they become closer and closer to product launch.
A huge thank you to our client who was gracious enough to let us use them as a starting point for this series.